PyPaDRE Concept¶
Goals¶
PaDRE (Platform for mAchine learning and Data science REproducibility) provides a platform to collect, compare and analyze machine learning experiments in a systematic and open way. It builds on Open Science principles and strives for improving research and education processes in disciplines related to Machine Learning and Data Science.
PyPaDRE is the Python-centric environment to create and execute Machine Learning and Data Science experiments. It aims to be a minimal-invasive environment for evaluating Machine Learning and Data Science experiments in a systematic and structured way. While PyPaDRE can be used as standalone, local solution for running and comparing experiments, all results can - and in the spirit of Open Science should - be made available via the PaDRE platform.
Use Cases¶
Rapid Development Support¶
Padre’s first use case is for rapid development by reducing scaffolding scientific experiments. Users should be given
easy access to datasets
convenience functions for setting up experiments
running the experiments
comparing and visualising results
packaging and deploying the experiment
Every experiment run should be logged in order to keep the experiments traceable / comparable.
Hyperparameter Optimization¶
After setting up an initial prototype, the next step is to do some initial hyperparameter tests. Padre should support this via a few lines of code and make it easy to analyse the optimized hyperparameters / runs.
Large Scale Experimentation¶
Large scale experimentation aims at a later stage in the research cycle. After developing an initial prototype there is often the need to setup larger experiments and compare the different runs with each other, show error bars, test for statistical significance etc. Large scale experimentation aims to define an experiment and hyperparameters to be tested and to deploy the experiment runs over a larger cluster. Results could be checked online and compared online using web-based visualisation. Results can be converted in different formats (e.g. latex, markedown).
Visual Analysis and Collaborative Exploration¶
Experimental results should be visualised / analysed in a interactive frontend and potentially discussed with others.
Interactive Publishing and Versioned Result Publishing¶
Experimental results should be accessible online and embedded in online publications (e.g. Blogs). When new versions of experiments are available, a new version of the online publication should appear. The versions need to be trackable.
Research Management and Collaboration¶
Managing a smaller (PhD) or larger (funded project) research project should be fully supported by padre. This includes
source code management
experiment management and evaluation
formulation of research questions
collaboration on experiments, interpretation and writing
issue tracking and discussion
Architecture¶
The following figure shows the overall architecture.
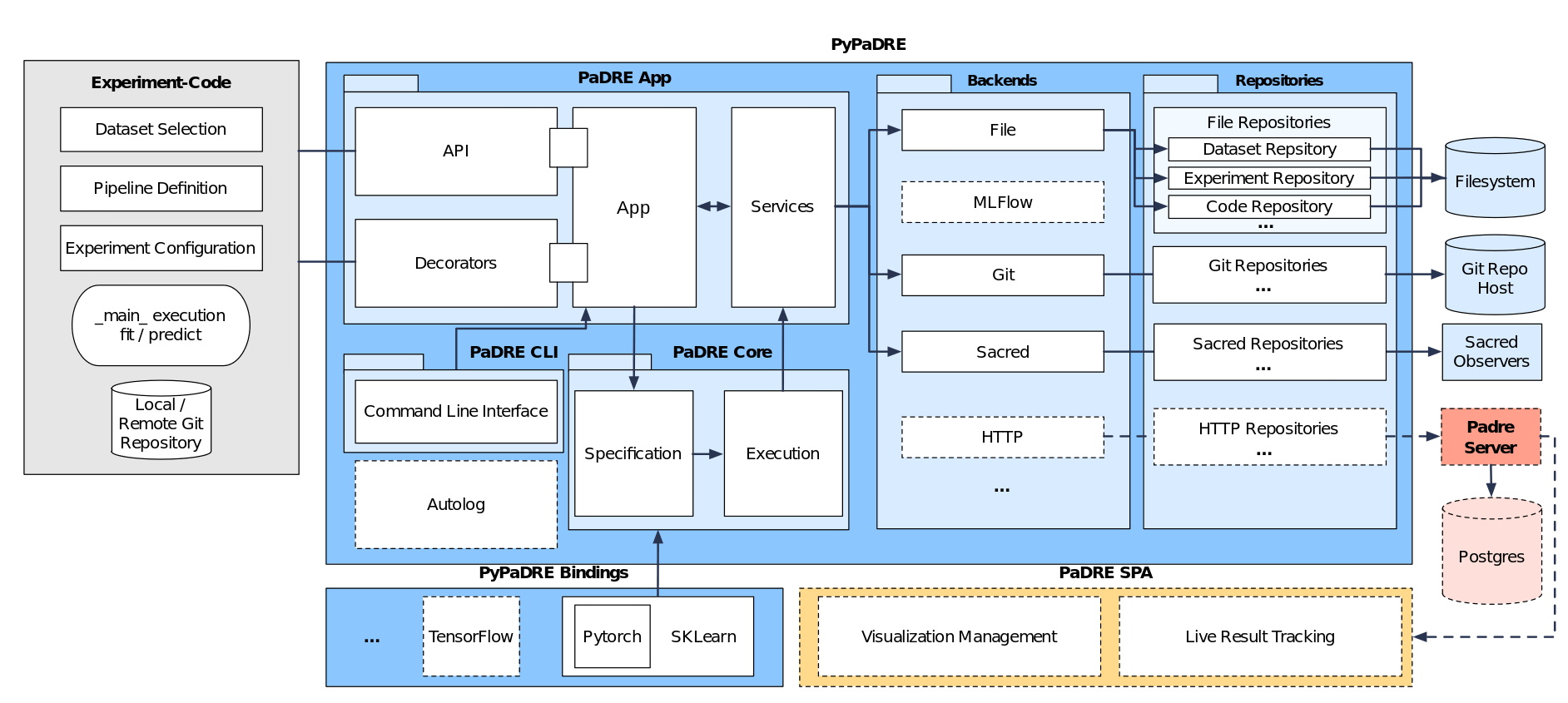
PyPaDRE provides means to
Manage local and remote data sets
Create, run and compare experiments
Automatically identify hyperparameters and components of workflows from SKLearn and PyTorch
Provide an easy to use Python and CLI interface
Automatically version datasets, hyperparameters, code etc required for the experiment
while being minimally invasive.
Researchers should use their favorite tools and environments in order to conduct there research while PyPaDRE takes care of managing resources and experiments in the background.
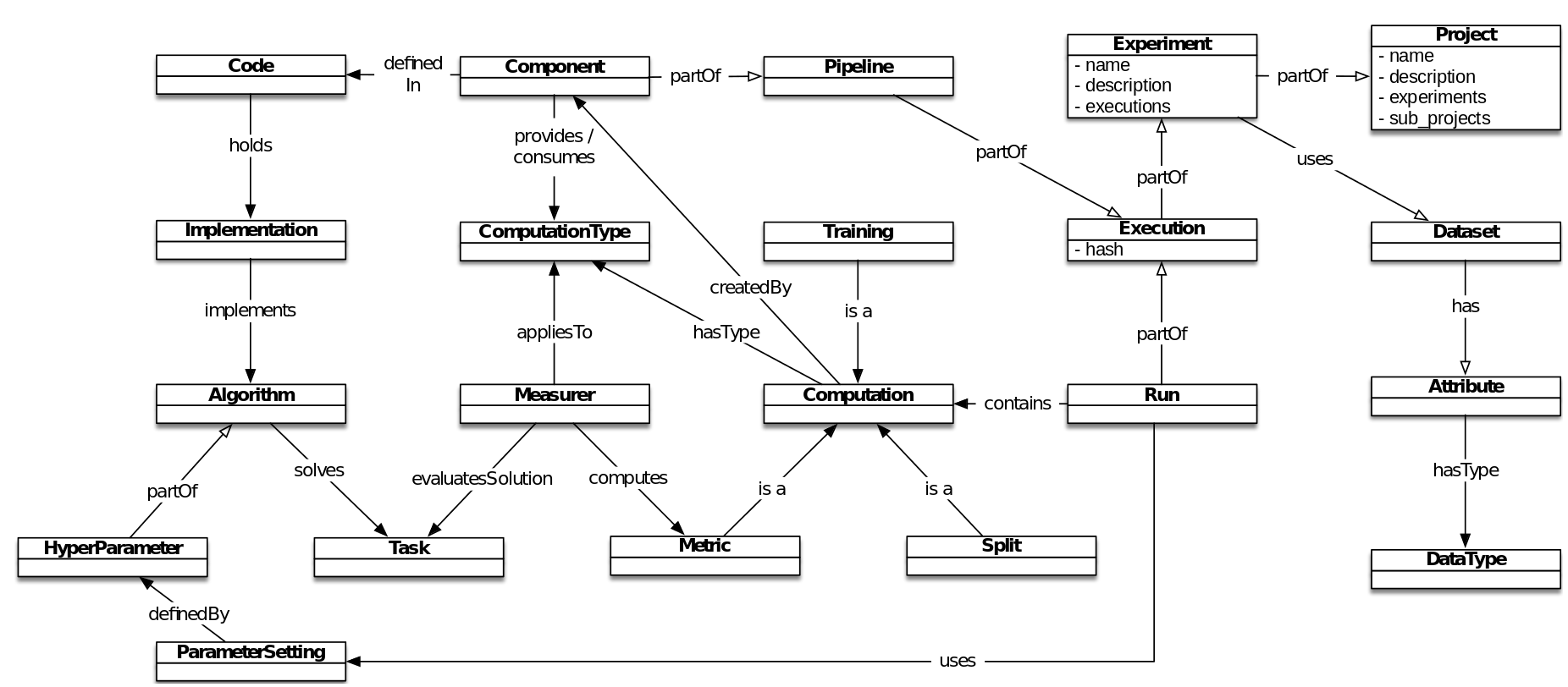
This image shows the different parts of an experiment and how they all work together in the PaDRe architecture.
Experiments and Pipelines¶
In order to do so, PyPaDRE defines four core concepts: pipelines, experiments, runs and splits.
Pipelines/Workflows are the actual machine learning workflows which can be trained and tested. The pipeline is composed of different components which are basically data processes that work on the input data. They can be preprocessing algorithms, splitting strategies, classification or regression algorithms. PaDRe currently supports custom code, SKLearn pipelines and the PyTorch framework within SKLearn pipelines.
Experiments define the experimental setup consisting of a pipeline (i.e. the executable code), a dataset, and hyperparameters controlling the experiment as well as parameters controlling the experimental setup (e.g. splitting strategy)
Executions are running of the workflows which are associated with a particular version of the source code. If the source code is changed, it results in a new execution.
Runs are single executions of the pipelines. Each time the experiment is executed a new run is generated in the corresponding execution directory.
Computations are the actual executions of a run, i.e. the execution of the workflow, over a dataset split.
In general, users do not have to care about Executions, Runs and Components. They need to implement their pipeline or machine learning component and wrap it with the wrapper PaDRe provides. Additionally, a experiment configuration needs to be provided including a dataset. When executing the experiment, PyPaDRE stores results and intermediate steps locally and adds it to the database of experiments. Afterwards, it provides easy means to evaluate the experiments and compare them, as outlined below.
For more details please refer to Setting up Experiments :ref:<setup_experiments>.
Components and Hyperparameters¶
Hyperparameters are distinguished between
model parameters: parameters, that influence the model
optimizer parameters: parameters, that influence the optimizer
other parameters: parameters, not fitting into the above classes
Hyperparameters can be specified by the individual components directly in code (recommended for smaller experiments) or via a mappings file, which is a json file that links metadata to the implementation in a library. The mapping file also provides an extensible mechanism to add new frameworks easily. Via an inspector pattern padre can extract from relevant parameters and components from an instantiated pipeline.
Components follow some implementation details and provide fit, infer and configuration commands.
Experiment Evaluation¶
Experiments should store the following results
Raw Results currently consisting of regression targets, classification scores (thresholded), classification, probabilities, transformations (e.g. embeddings).Results are stored per instance (per split).
Aggregated Results are calculated from raw results. This includes precision, recall, f1 etc.
User Defined Metrics are computed based on user provided code. The user can implement their own functions and wrap it with the PaDRe structure to provide custom metrics. This code is also versioned and stored as a code object.
Evaluation should include standard measures and statistics, but also instance based analysis.
Research Assets Management¶
Beyond experiment support, the platform should also help to manage research assets, like papers, software, projects research questions etc. Currently, these artifacts can be managed via adding them to the source code folder and let it be Git managed.
Metasearch and Automated Machine Learning¶
Not Yet Implemented
Python Class Interface¶
First, when knowing the details of all packages PyPaDRE can be used in code.
This is either done by creating an padre.experiment.Experiment or
through using decorators (currently under development). However, in this case
the user is responsible for using the correct backends to persist results to.
app = example_app()
@app.dataset(name="iris",
columns=['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)',
'petal width (cm)', 'class'], target_features='class')
def dataset():
data = load_iris().data
target = load_iris().target.reshape(-1, 1)
return np.append(data, target, axis=1)
@app.experiment(dataset=dataset, reference_git=__file__,
experiment_name="Iris SVC - static seed", seed=1, project_name="Examples")
def experiment():
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
estimators = [('SVC', SVC(probability=True))]
return Pipeline(estimators)
Please note, that this is not the standard case and proper evaluation classes are currently under development.
Python App Interface¶
As a second interface, PyPaDRE support a high-level app. This high-level app integrates experiments, configuration files in a high level, easy to use interface.
from pypadre.core.model.project import Project
from pypadre.core.model.experiment import Experiment
from pypadre.binding.metrics import sklearn_metrics
self.app.datasets.load_defaults()
project = Project(name='Test Project 2',
description='Testing the functionalities of project backend',
creator=Function(fn=self.test_full_stack, transient=True,
identifier=PipIdentifier(pip_package=_name.__name__,
version=_version.__version__)))
def create_test_pipeline():
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
# estimators = [('reduce_dim', PCA()), ('clf', SVC())]
estimators = [('SVC', SVC(probability=True))]
return Pipeline(estimators)
id = '_iris_dataset'
dataset = self.app.datasets.list({'name': id})
experiment = Experiment(name='Test Experiment', description='Test Experiment',
dataset=dataset.pop(), project=project,
pipeline=SKLearnPipeline(pipeline_fn=create_test_pipeline, reference=self.test_reference))
experiment.execute(parameters={'SKLearnEvaluator': {'write_results': True}})
Python CLI Interface¶
The third interface is a command line interface for using Python via a command line. Please note that not all functions are available. Project and Experiments can be created via the CLI while computations, executions and runs can only be listed or searched. This is because the execution, runs, and computations have specific semantic meanings and are created while executing an experiment.